Bonjour, bienvenue dans la documentation du projet "La parole en lumière".
Ce site est la pour archiver et documenter mes recherches sur mon projet de q1 de design numérique.
Si vous cherchez uniquement à obtenir des informations précises et pertinentes cette page n'est pas faite pour vous.
Une version traitant de manière plus restrainte le coté technique existe ici
- instalation sonore avec une piste son séparées en fonction des fréquences, jouant une pièce sonore automatisée avec des programs géneratifs.
- projet autour de la "parole" des animaux
- création d'une série de tutoriels vidéos sur des sujets numériques avec des ia. (inspiré de la vidéo de Jul qui explique le théorème de Thales)
- Création d'histoires audio d'horreurs avec des voix géneratives et du sound design
C'est à cette étape que je présente pour la dernière fois mon projet à la classe avant les cotations. Les professeurs ont l'air content que j'ai enfin le début de quelque chose de concret à présenter mais sont d'accord avec moi : le projet est dans un entre deux, traitant d'avantage du son que de parole. Il faut que je trouve un moyen de mieux intégrer cette dernière dans mon système. Si je n'ai jamais vu de système de reconaissance vocale dans TD, ça doit bien etre faisable. (spoil:ça l'est) Je pars donc du dernier cours avec un objectif ! (spoil2: j'ai pas réussi).
Je me suis jamais trop renseigné sur la reconaissance vocale, j'aime pas les assistants vocaux, encore plus depuis qu'ils sont intéligents. Néanmoins je me dis que les progrès technique va au moins me faciliter la vie. Je commence mes recherches sur des solutions de reconaissances vocales interne à touch designer :
rien ne semble avoir été pensé directement pour cette fonctionalité dans le logiciels mais quelque rares personnes ont créés des choses qui s'en rapproche. La plus part utilisent un système d'api pour intégrer des modèles d'IA dans le logicel. C'est notament le cas de ce mec que je déteste désormais. Il a développé des composants TD facilitant l'utilisation d'open Ai et d'autres IAs et à innondé le web de pub pour son produit. a chaque fois que je croyais trouver une solution ou une explication je tombais encore sur lui
et ses produits. Forums, youtube, github, docu td officielle, etc.. Je le déteste.

Je réussis tant bien que mal à comprendre deux trois trucs sur les api mais sans réussir à en sortir une finalité intéressante pour mon projet. Je découvre "whisper ai" une i.a. de reconaissance vocale qui semble "facile" à utiliser, les gens s'en servent pour créer des assistants vocaux dans TD à partir de chatgpt. Je me dis que créer un système de fact checking live d'analyse de discours politiques serait possible. Un sytème de fact checking avec de l'ia. Oui. Cette idée me fait arreter de tripatouiller chat gpt pour en tirer quelque chose. Je me dis que si je n'arrive pas à inporter un système de reconaissance dans TD il me suffit d'en créer un autrement ailleurs et de transférer les donées. (j'étais encore pleins d'optimisme, so cute)
Sortir de TD me permet de re-repenser mon projet, je me dis que TD n'est pas le seul moyen de faire un système live, et que ça pourrait également prendre la forme d'un site rajoutant une notion de publication chère à la section DN. J'abandonne l'idée d'un système lumineux comme finalité, ce médium me semble plus intéressant à traiter d'un point de vue musical en tout cas pour mon approche personelle et me limite dans mon exploration. Je me renseigne sur d'autre outils qui me permetraient de faire rette retranscription textuelle en live d'un discour oral. Tout ça me guide vers des librairies python. J'y connais rien mais j'adore les serpents à la base moi donc why not ?
Alors là, c'est ici qu'on commence à s'amuser (ou pleinement sombrer). Mon objectif est SIMPLE : réussir à utiliser la librairie python "speech_recognition", une librairie permetant d'accéder à plusieurs moteurs de reconaissance vocale, pour certains sans à avoir à utiliser d'api. J'ai également besoin de "pyaudio" une librairie permettant à python d'accéder à mon microphone. (Pour py audio j'ai besoin d'installer "portaudio" mais ça j'ai vraiment pas compris ce que c'était concretement, ça permet de connecter pyaudio à mon micro physique je crois). Pour installer tout ça je doit passer par mon terminal en utilisant la commande "pip" ou "pip3", ça permet d'aller chercher les librairies (ou ça ? Dans un gros cloud auquel on est tous connecté ?). Tout ça me semble bien trop technique pour moi on va dire que l'important c'est que ça marche.
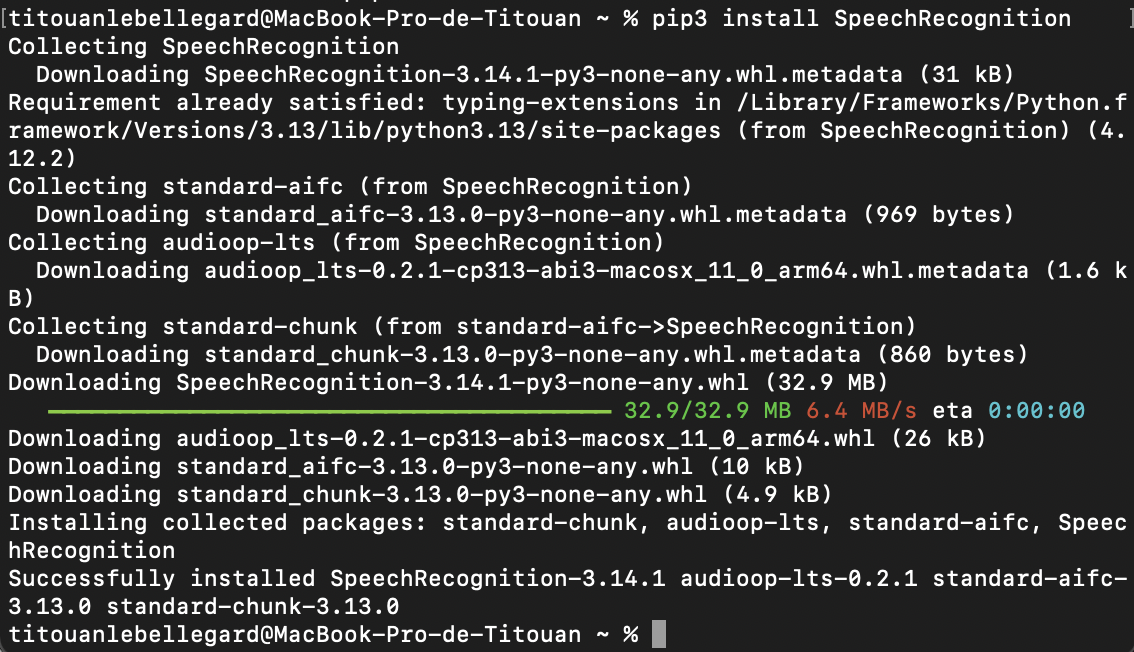
Ah ben sauf que ça marche pas.
Enfin si.
Mais en fait non.
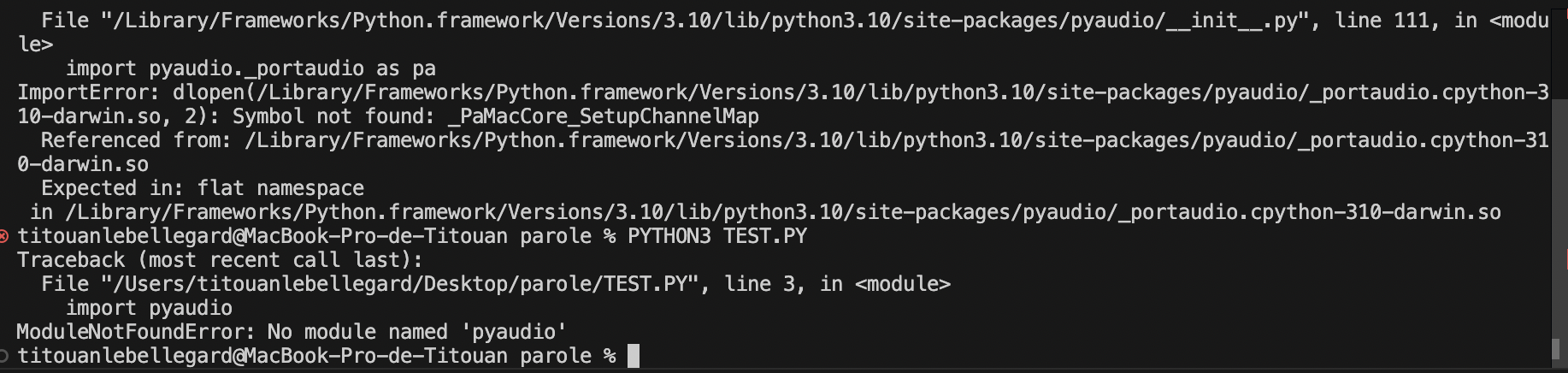
C'est surement très simple quand on est habitué, mais j'avous je pige que dalle. Je galère déjà a retrouver ou fl enregistre mes projets alors les fichiers sans visuels auxquels j'ai pas accès avec ma souris .. C'est ici et dans le terminal de vs code que j'ai passé mes deux dernières semaines à essayer de trouver la combinaison qui marche. Askip c'est en faisant des erreurs qu'on apprends donc voici une liste des erreurs/problèmes que j'ai rencontrés, que j'ai (partiellement) comprises, et les solutions que j'ai trouvée pour tacher d'y remédier.Je crois que le premier problème est d'utiliser le bon python. J'ai une version 2.7 déjà préinstallé que je n'ai pas supprimé quand j'ai instaler la 3.14 en Art num. La version 2.7 ne prend plus en compte les librairires que je veux utiliser, et la 3.14 est trop récente. Je doit donc installer un nouveau python. J'ai essayé plusieurs versions entre la 3.10 et la 3.14 en suivant des tutos et des discussions de forums. Après je sais pas combieen de tentatives j'arrive à installer les 2 librairies et là : incroyable j'arrive à lançer speech_recognition dans le terminal. Victoire !
Je pensais avoir enfin franchis cette montagne, mais le landemain (après avoir remit une heure à retrouver la commande qui lance le programme ) je suis confonté à un nouveau problème: effectuer mon programme dans visual studio.
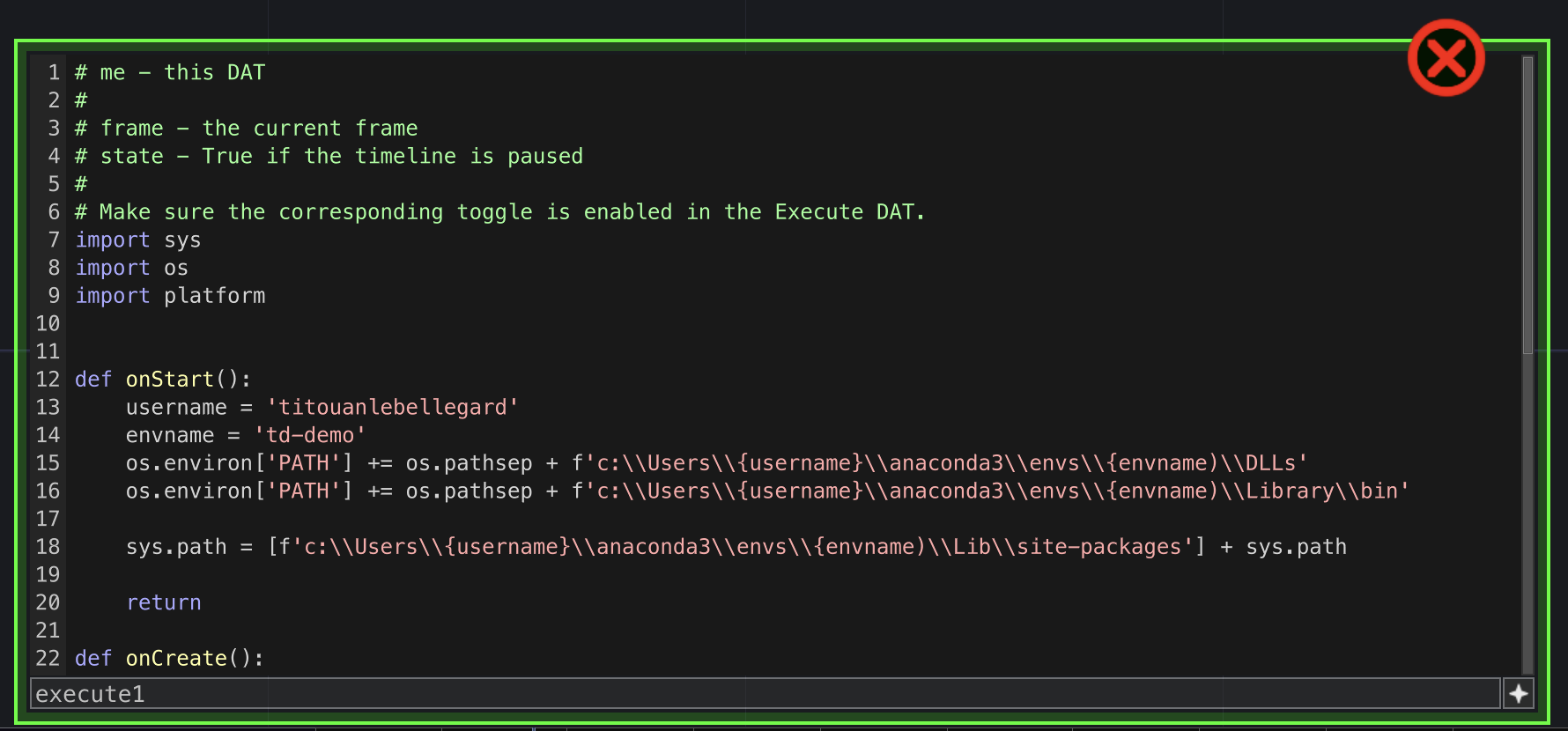
Je décide de rouvrir touch designer, touch designer permet d'utiliser python (en utilisant les blocks "DAT's") pour exécuter des scripts. Je me dis que peut etre comme ça ça va fonctionner ? Je me renseigne donc sur python dans TD, et de tuto en tuto je tombe sur une vidéo de quelqu'un qui explique comment importer des librairies pythons dans TD, jackpot il utilise speech_recognition pour son exemple ! (comble de l'ironie il n'y arrive pas et fait avec une autre librairie en nous disant que c'est plus compliqué pour speech_recognition mais que ça fonctionne pareil). Je regarde donc d'autres tutos et docus sur le sujet. En fouillant je tombe sur la notion de "virtual environement" qui semblerait etre une solution à mes problèmes. Un virtual environement si j'ai bien compris est une sorte de dossier/cloud dans lequel toutes les parties prenantes s'articulent dans un écosytème commun. Ça permet notamment de préciser quelle version de python utiliser avec tel logiciel. Ma version de td, la 099, utilise python 3.9. Je doit donc crééer un venv utilisant python 3.9, y importer les packages depuis le terminal et réussir à tout faire fonctionner. Je me renseigne sur anaconda, un système de venv conseillé dans les tutos. A ce moment là, Sable a tenté de m'aider, grace à elle j'ai pu créer mon venv, le connecter à python 3.9 et à y importer les librairies. Reste à le connecter à touch designer.